Network Address Translation(NAT)
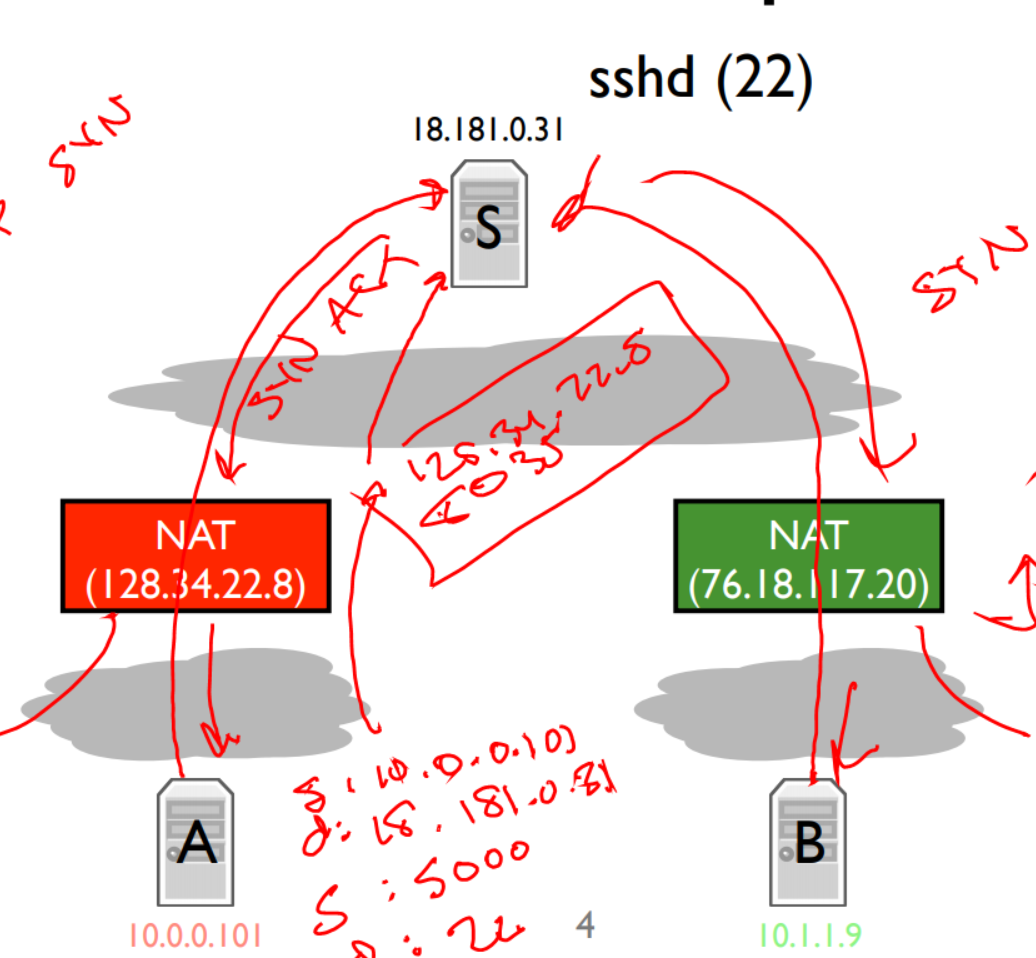
NAT 的作用是暴露一个公共的IP,外部流量想访问内网时会先经过NAT,然后NAT把流量转发给对应的内网主机。这样就不用每个设备都占用一个公共的IP了,但这也产生了新的问题,NAT后的IP都是NAT来管理并分配的,外网怎么能拿到NAT后的IP并发起连接呢?
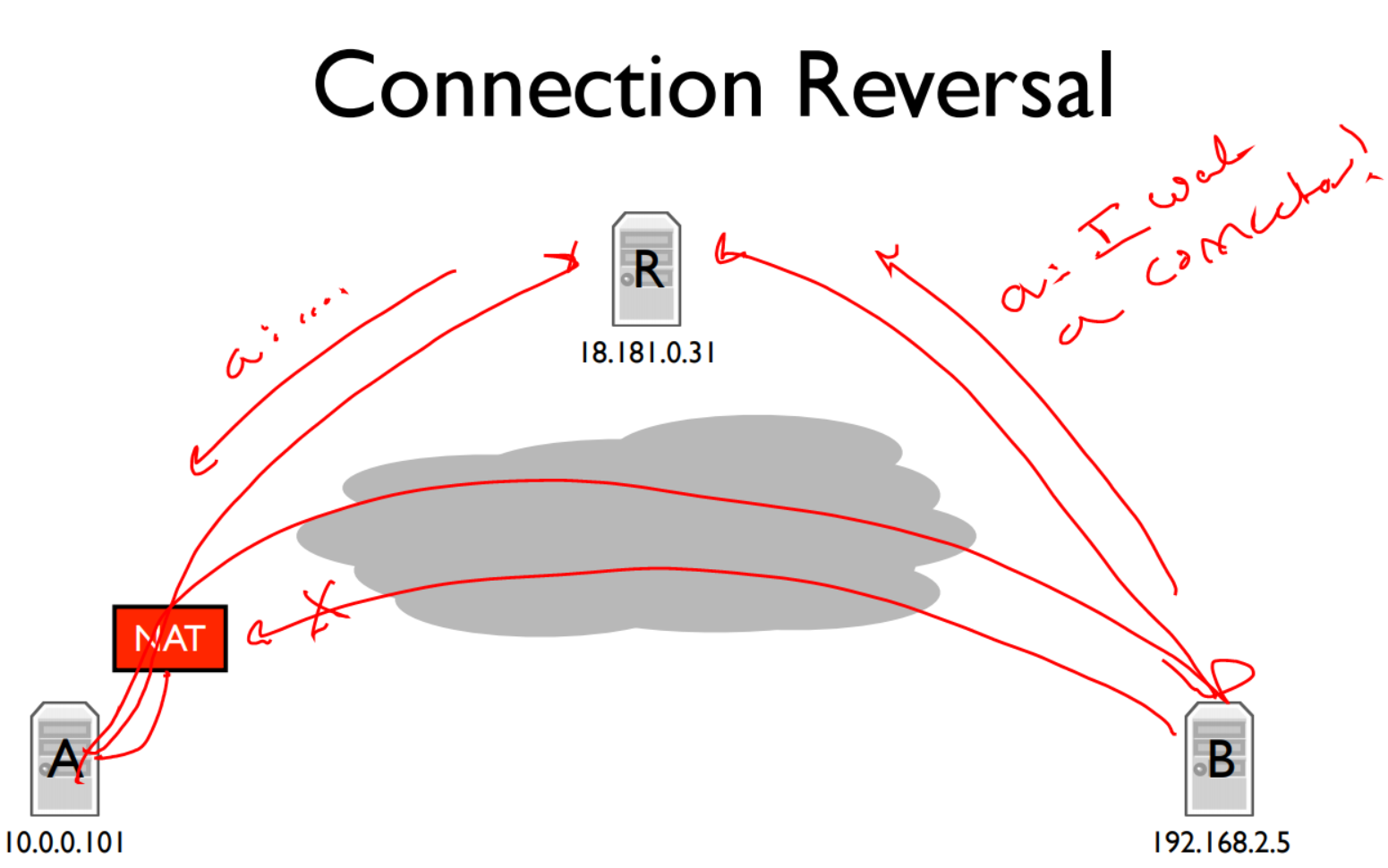
现在A在NAT后面,B想访问A,但是现在NAT中没有B到A的映射,自然无法访问到A。此时就需要rendezvous service,图中的R提供rendezvous service,首先A和B都会在R中注册。如果B想连接A,它会先想R发出请求,然后R携带着B的地址向A发出请求,A再来反向连接到B,以此来建立A和B之间的连接。
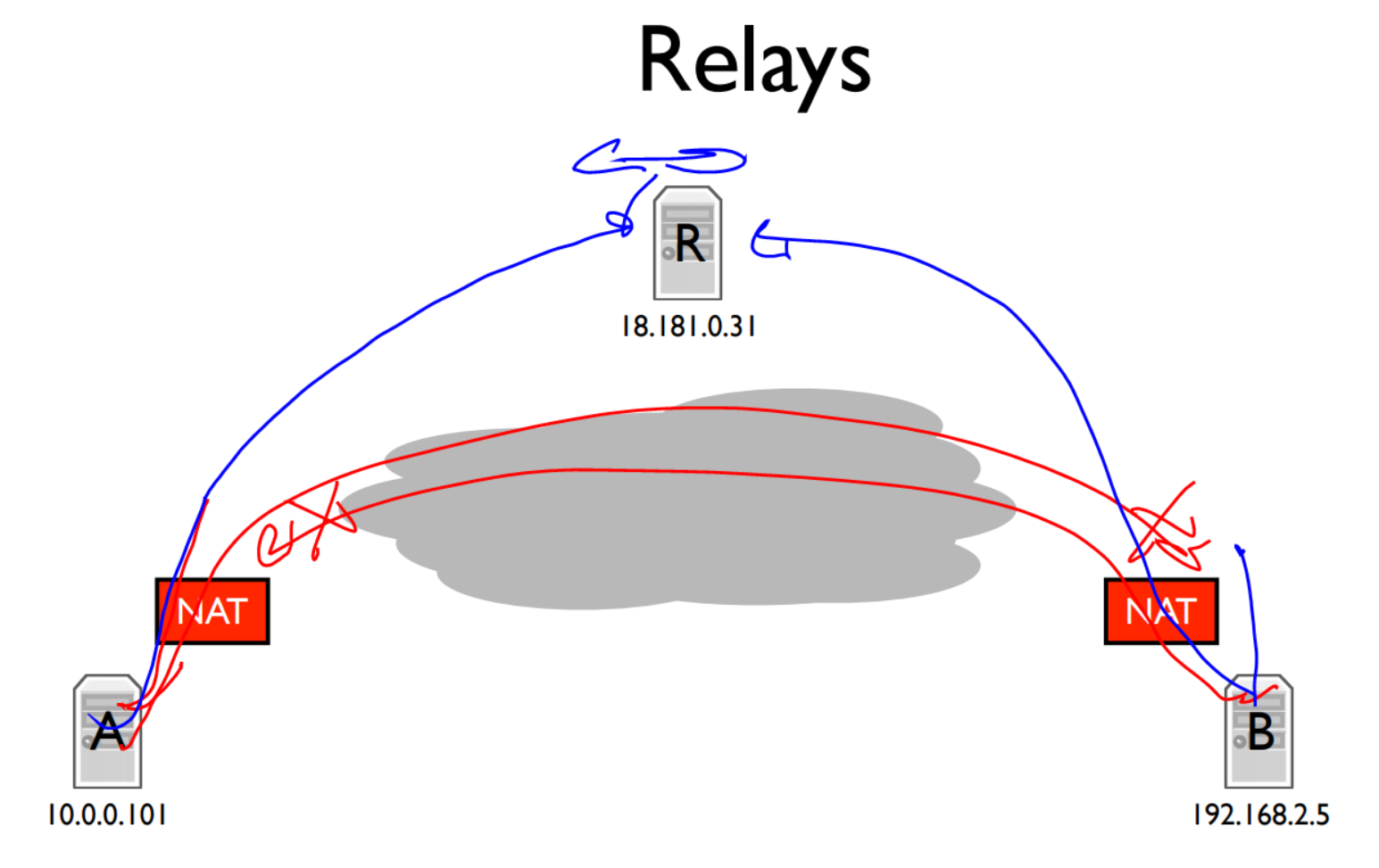
如果A,B都在NAT后面,A、B想要连接彼此都需要先找R,R做中继来转发A、B的流量。
HTTP

HTTP协议即超文本传输协议,那么什么是超文本?超文本指的是一个文档格式,使得我们可以把一些格式和内容信息放到一个文档中。超文本由ASCII字符构成。
HTTP Request Format
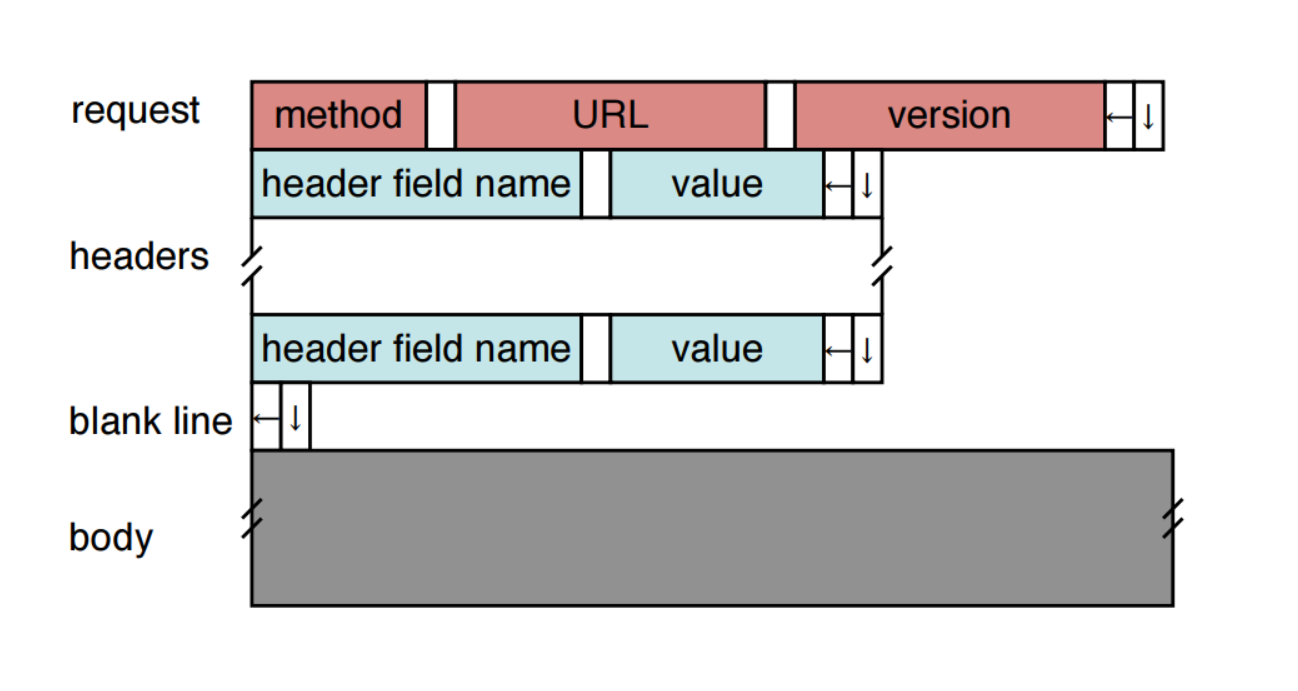
HTTP会携带请求的方法(GET、POST…),应用于该方法的URL,HTTP版本。中间的空白是空格。左箭头意味着回到该行的开头,下箭头意味着进入下一行。
request本身可以有一个或多个header,一个header占一行,每一个header都是以header field name、value这样的顺序排列。
header部分结束后是一个空行,紧接着就是request body。如果是GET请求自然body是空的,但是HTTP支持多种请求比如发POST的时候body就会被填充成你需要发送的数据。
HTTP Response Format
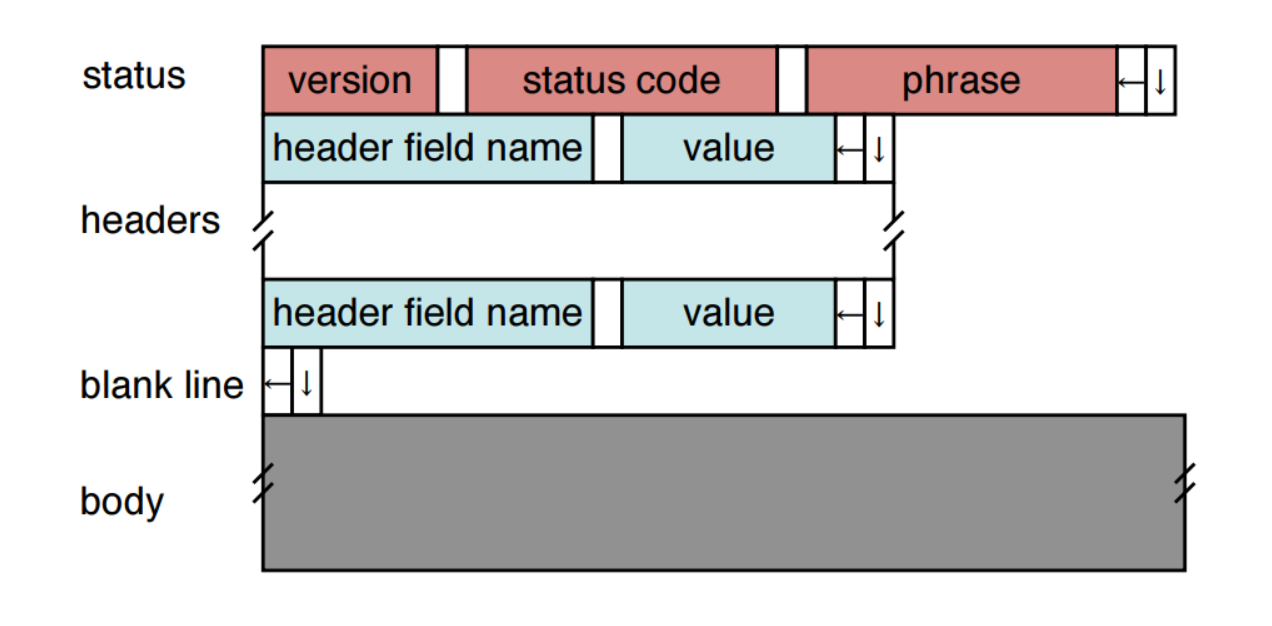
Response和Request的结构相似,首行是HTTP版本,状态码,状态码的描述。比如200 OK、404 Not Found等。Response的header也是可以有一个或多个,然后空行,最后是Response body。
这里补充一点,有一个Header叫if-Modified-Sinces它的值是一个时间戳,表明从此时起这个页面就没被修改过了。假如有一个response返回304这意味着这个页面没被修改过,现在看到的页面实际上来自浏览器缓存,而不是从服务器拿来的数据。
HTTP 1.0

HTTP 1.0做的事情非常简单,支持GET请求,客户端发送请求后做出相应,最后关闭连接。如果想再次请求则得再次重复三次握手建立连接。

HTTP 1.0的问题在于如果返回的网页中含有多个媒体资源,那客户端得多次请求服务端返回媒体资源,这意味着多次握手与挥手,同时因为TCP的发送窗口一开始是很小的,而HTTP每次连接传输的内容又比较少,TCP窗口还没有增长到链路的极限时数据就发送完了,造成链路的利用率低下。
HTTP 1.1

HTTP 1.1会携带一个Header告诉服务器是否应该在相应后保持连接(当然,是否在相应后保持连接由服务器决定)。response会包含一个Connection header,通过它来告知客户端服务器想做什么。如果服务器决定keep-alive这个连接,那么keep-alive这个header将会告诉客户端连接会保持多久。现在,客户端可以利用一个连接发送更多request。
SPDY

SPDY是谷歌开发的新协议,思想是异步的返回所需的资源,如果有的资源相应得很慢,可以先把能响应的资源的返回给客户端,而不是像以前一样等所有资源都就位了才打包发送。
BitTorrent
BitTorrent采用去中心化的思想,客户端得到文件不再是从单一服务器中获得了,而是从其他客户端中取得。为了使单个客户端能并行从多个客户端获取文件,BitTorrent把文件分解成多个块,当一个客户端下载了一个块时,会通知其他客户端,这样其他客户端就可以从那里下载了。这样相互协同的客户端集群被称为swarms。
Torrent Files

BitTorrent把文件分成N块,每块256KB或者更大,规定这个大小是为了确保TCP流传输文件时能让TCP窗口增长到一个可以充分利用链路的大小,BitTorrent也会把块再分成子块,这样就可以向拥有这一个块的多台机器来发送请求以此来降低延迟。块也是检查文件完整性的一个单位,一个torrent包含每个块的SHA1码。
关于这文件完整性,这里有一个故事。2006年HBO发行了一部新剧《Rome》。当时有几个不同的torrents可以用来下载这部剧,它们中的每一个都有着很大的swarm,但是大家发现无论如何都利用这几个torrent来下剧,原因是在swarm中有一些速度极快的peer(这会导致其他client优先从这个peer中下载块),但是这些peer提供的块的哈希是不匹配的。所以其他client从这些peer中下载块后,然后发现哈希不对,扔掉这个块,然后再请求这个peer,一直重复这个过程。大量的client进入这个无尽循环。有说法是HBO设置了这些peer,为的是防止盗版。现在client可以设置黑名单,如果一个peer提供的块是损坏的那就会进入黑名单,并不再从该peer中获取数据。

peer会周期性的交换信息以此来知道每个块在哪台主机上,客户端会优先下载最稀有的块,如果单个块不可用了,没人能下载完整的文件,所以,如果只有几个client有块,它们将成为下载时的瓶颈,这被成为稀有优先原则。如果一个客户端几乎下完了文件,只有几个块没下载时,它将向多个peer做出请求。这是为了防止最后一个块来自一个很慢的peer,导致整体下载很慢。

如前所述,客户端会交换元数据来定位块的位置,但假如一个客户端向所有peer提供块,它可能开启上百个TCP流,那对于其他peer来说,其实获得块的速度实际上是很慢的。BitTorrent的做法是每个peer只开启几个TCP流,每个peer在一个小范围内相互发送数据。以此来提升速度。BitTorrent计算出从每个peer得到数据的比率,然后从中选出最好的几个peer,然后再相互交换数据。
DNS


DNS服务是只读,或读远远大于写的。同时允许弱一致性,不同的用户可能在同一时间得到不同的结果。
DNS Name Architecture


A DNS Query

有两种DNS查询:递归和非递归
递归查询会逐级向上查询,非递归查询只会查一个服务器。
DNS通常使用UDP和53端口。
递归查询:先查找最近的DNS服务R,如果没结果,R将会向根服务器发出非递归请求来询问管理这个顶级域名的服务器是谁,然后R缓存这个顶级域名服务器的信息,同时向顶级域名服务器查询domain域名,再查询domain服务器。最后返回。
为什么DNS又要用TCP又要用UDP?
首先UDP报文长度最大为512字节,而TCP允许报文长度超过512字节,当DNS查询超过512字节时,协议的TC标志出现删除标志,则这时使用TCP发送,通常传统的UDP报文一般不会大于512字节。
区域传送时使用TCP,主要有两个原因:
辅域名服务器会定时(一般是3小时)向主域名服务器进行查询以便了解数据是否有变动。如有变动,则会执行一次区域传送,进行数据同步,区域传送使用TCP,因为数据同步传送的数据量比一个请求和应答的数据量要多得多。
TCP是一种可靠的连接保证了数据的准确性。
域名解析时使用UDP协议:
客户端向DNS服务器查询域名,一般返回的内容都不超过512字节,用UDP传输即可,不用TCP三次握手,这样DNS服务器的负载更低,响应更快。虽然理论上说,客户端也可以指定DNS服务器查询的时候使用TCP但事实上,很多DNS服务器进行配置的时候仅支持UDP查询包。
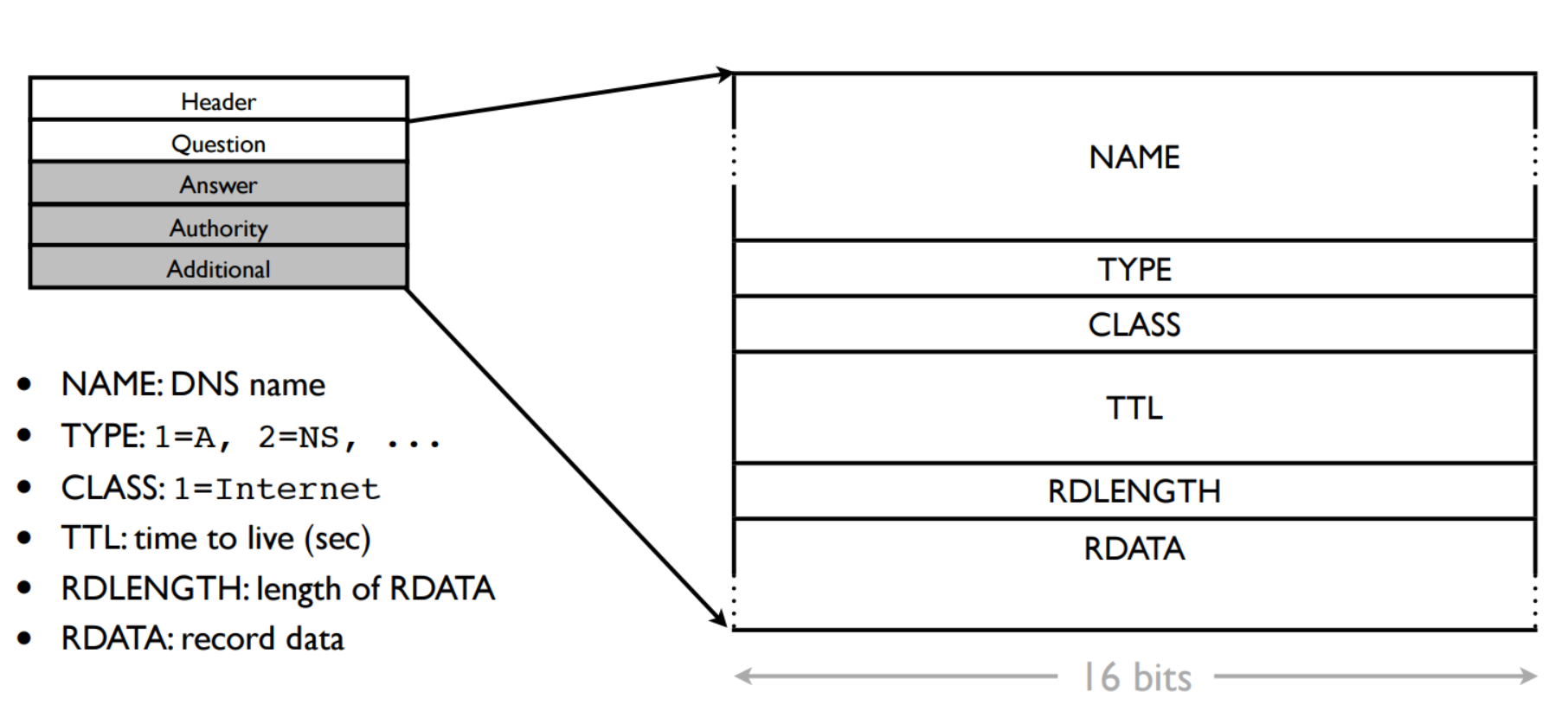
DNS Message Structure


Dynamic Host Configuration Protocol(DHCP)

DHCP的做法是一台机器在连接到网络时可以请求DHCP服务器来进行配置,比如分配一个IP,获得子网掩码等。这个配置的有效期由租约(lease)控制,当租约到期时需要更新配置。





