Buffer Pool

每当要读取一些不在buffer pool中的数据时,数据库就会先访问磁盘,然后把数据放到buffer pool中,再对buffer pool进行操作,最后落盘。很明显buffer pool中数据的排列肯定是和磁盘中的存储形式不是一一对应的,这就需要一个indirection层来指示特定的Page在buffer pool的哪个位置。
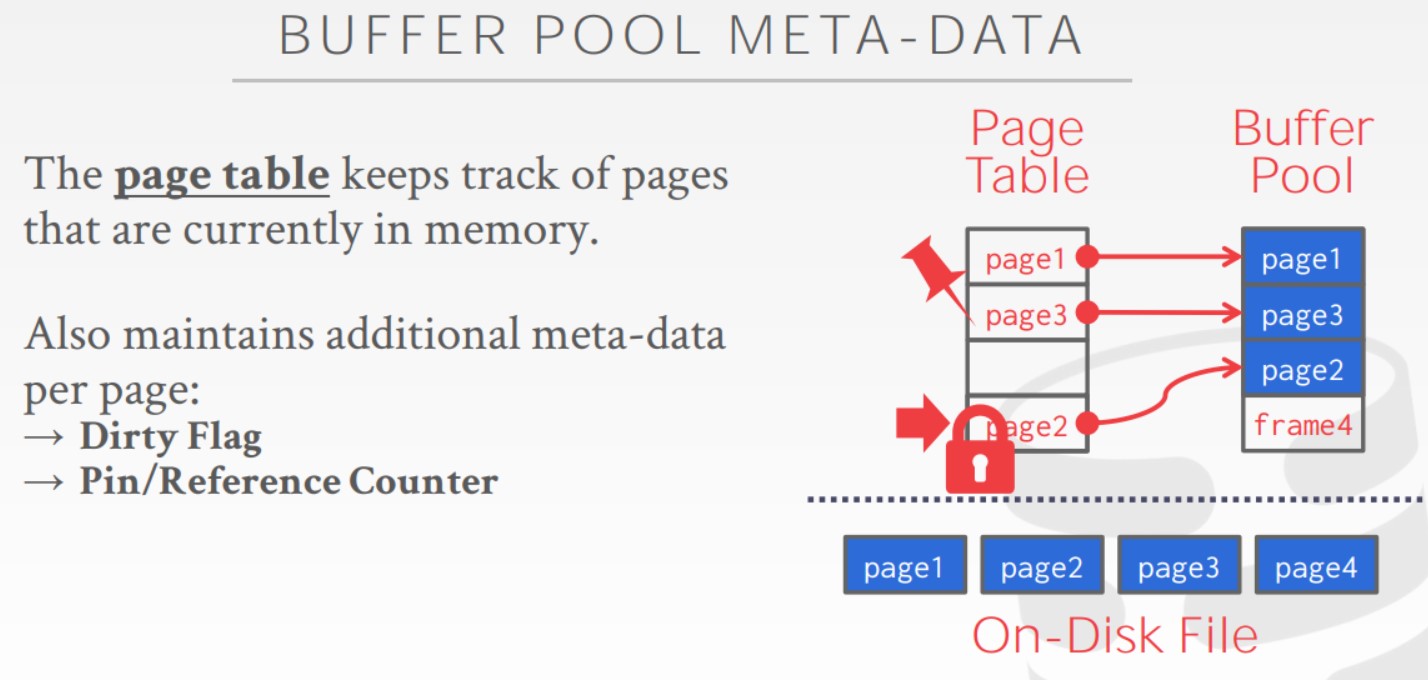
Page Table本质上就是一个hash表,用来追踪在内存中有哪些Page,如果我们想找一个特定的Page,通过Page Table和Page id就可以知道这个Page在哪个frame中。由于事务的原因,数据库必须维护一些额外的元数据,以此来追踪当前buffer pool中发生了什么。
- Dirty Flag:用于指示从磁盘读取到Page后,这个Page是否被修改
- Pin/Reference Counter(引用计数):用于追踪想要使用该Page的当前线程数量或者正在查询该Page的线程数量。这也意味着我现在还不想把该Page落盘,因为可能还有线程在对该Page进行更新。
正因为需要数据库自己维护这些东西,所以说mmap是个不好的做法,因为OS根本不知道应该在什么时候将内存中的数据落盘。
Lock 与 Latch

在数据库中Lock是更高级的逻辑原语,它会去保护数据库中的逻辑内容,例如:tuple、表以及数据库。事务运行时会去持有这个Lock。
Latch是一种底层保护原语,我们使用它来保护数据库系统内部的关键部分,比如保护数据结构和保护内存区域,所以在执行操作期间,我们会持有这些Latch,用来保护某些东西,比如在更新Page Table时会在要修改的地方加上一个Latch,修改完后将其释放。
Page Table 与 Page Directory

Page Directory的作用是找到Page在数据库文件中的位置,所以我们必须对Page Directory做出的所有改变都进行持久化。因为如果系统崩溃了,恢复以后我们想要知道该在哪里找到对应的Page。
Page Table是内存中的映射,它将Page id映射到它们在buffer pool中frame的位置,所以这个东西可以是暂时的,因为如果崩溃又恢复后buffer pool里早就没内容了,也没必要再去在意Page Table。
Multiple buffer pools

在真实的数据库实现中Buffer Pool可能会有很多个,可能每张表一个Buffer Pool也可能每个数据库有一个Buffer Pool,这样做的目的在于我们可以在每个Buffer Pool上使用不同的局部策略,为其所维护的数据来量身定制,比如可以为一张表设置两个Buffer Pool一个用于索引查询,一个用于全表扫描。另一方面多Buffer Pool的模式可以减少多线程之间争抢Latch的情况。MySQL在这方面的做法是由用户指定需要多少个Buffer Pool,然后对于一个给定的Page id,它会通过Round-robin hash来判断这个Page在哪个Buffer pool中。
预读
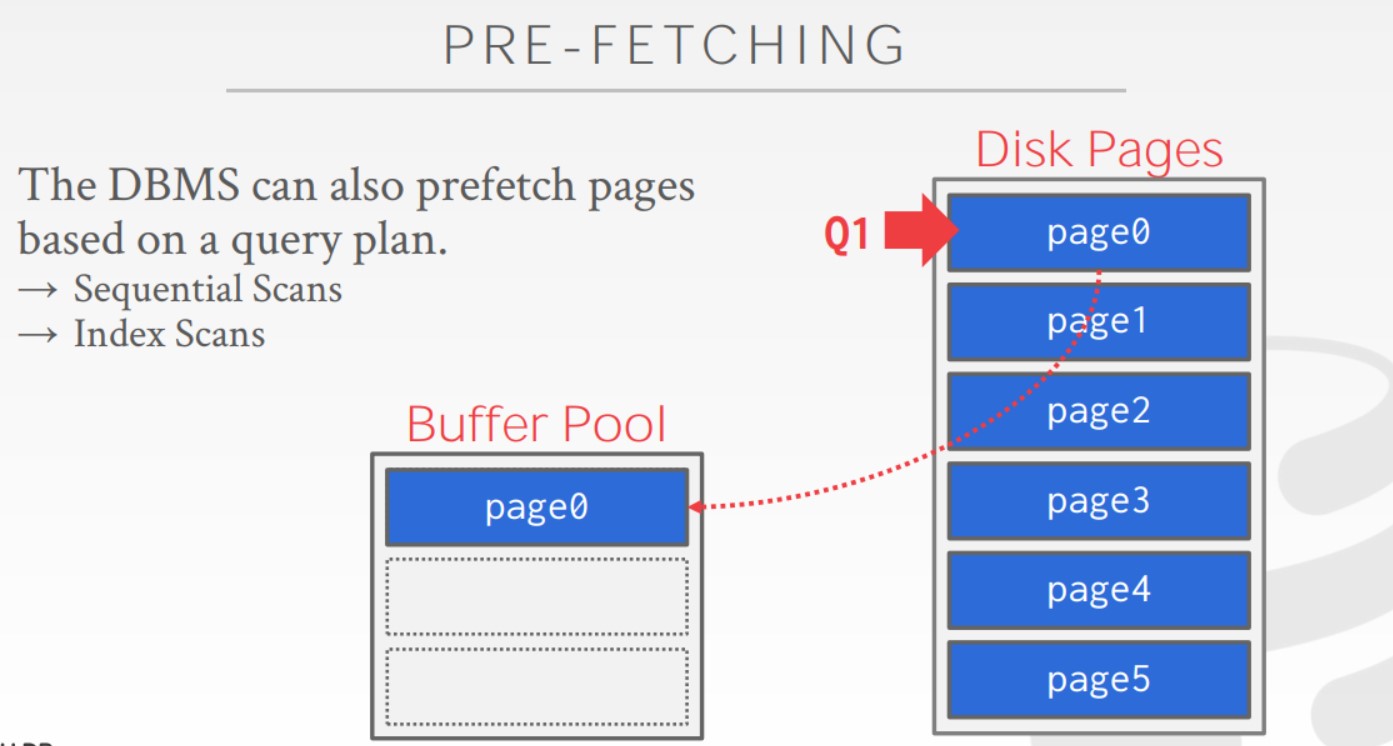
在数据库想读Buffer Pool中的某些Page时,可能这些Page还没有装载进Buffer Pool而,于是线程得阻塞,等到Buffer Pool装载完毕后再继续工作。假设我要读某张表的全部tuple那这样一个Page一个Page的读入Buffer Pool明显效率很低,因为线程得频繁的进入阻塞状态。因此产生了预读技术,数据库会先对SQL进行分析,然后知道要从磁盘中读取哪些Page,并将其成批的而不是单个的存入Buffer Pool,以降低线程的等待时间。
扫描共享

扫描共享的做法是利用其他查询的结果来加速自己的查询。这个技术和结果缓存的不同在于,结果缓存只是把结果保存起来,下一次运行一模一样的查询时再把结果读出来。而扫描共享是将上一个查询得到的Page再给下一个查询使用。

Buffer Pool PassBy

Buffer Pool Passby分配一小块内存给执行查询的那条线程,然后当它从磁盘中读取Page时,如果该Page不在Buffer Pool中,那么它必须从磁盘中拿到该Page,这里并不会将它放到Buffer Pool中,而是将它放入本地内存中,当查询完成后,所有这些Page将被丢弃。之所以这样做是为了避免去Page Table中进行查询所带来的开销,因为Page Table中的条目是带锁的。
操作系统页缓存

由于所有的软件都是在操作系统之上运行的,这也就意味着实际上各类软件最终还是要通过各种系统调用来完成相应功能。在默认情况下OS会去维护它自己的文件系统缓存,也即OS page cache。当数据库读取一个Page时,OS会在它的cache中保存一份副本,这样我有两份副本一个在OS cache一份在Buffer Pool,所以大部分数据库不想这种情况发生,数据库会直接调用direct I/O(直接内存I/O)来避免OS缓存内容。主流数据库中唯一利用OS page cache的是PostgreSQL。这样我们就可以利用PostgreSQL中的pg_prewarm来提前预读某个热点表,然后该表的所有查询就均是在OS缓存中进行的了。此时即使重启了PostgreSQL,清空了Buffer Pool依然可以快速的进行查询,因为OS的缓存还没有刷出。
Buffer Pool替换策略

在Buffer Pool存满时自然需要刷出一些Page来为新的Page留出空间。替换策略如何制定,也就是如何高效利用缓存,这在计算机科学中是一个经久不衰的话题,相比于商业数据库和开源数据,它们一个重要差别就是商业数据库有着非常复杂且高度优化的替换策略,而开源数据库这方面的实现相比之下要简单的多。
LRU

最近最少使用,每次使用Page时更新该Page的时间戳,替换时将最老的Page替换。
CLOCK

Clock是一种类似LRU的算法,在Clock中无需再追踪每个单个Page的时间戳,而是去追踪每个Page的标志位(reference bit),它标志着自从上次检查过该Page后,这个Page是否被访问了。所以,要将Page组织成为一个环形的Buffer,就像一个Clock,然后有一个能够旋转的指针来检查这个标志位是被设置成1还是0,如果是0,那么意味着自从上次检查后该Page没有被访问过了,可以将该Page从环形Buffer中移除。
在一开始所有的标志位都是0,假设某些查询访问了Page 1那么标志位置1无论后续Page 1又被访问了多少次,都仍然是1(这只是个标志位)。当需要替换一些Page时指针会从当前位置出发当看到Page的标志位是1时将其置0,然后指向下一个Page,如果该Page是0那么移除这个Page。
Sequential Flooding
无论是LRU还是CLOCK都有这个问题,当我顺序的读取一个表后,组成表的所有Page都被标记为最近被使用过,但是可能这些Page我都不会再去使用了,而Buffer Pool开始刷出时会把之前顺序读取前的Page刷出,留下那些刚刚读过但是不会再使用的Page。
LRU-K

当要替换Page时看的不是哪个Page的时间戳最老,而是看时间戳之间的间隔,寻找那个上一次访问和下一次访问间隔时间最长的Page,这里的K指的是保存历史时间戳的队列容量。
Localization

替换Page时从单个查询的视角来寻找应该被替换的Page,而不是从全局的角度来看哪个Page使用的最少。
Priority Hits

当有索引时,就可以知道查询是如何进行扫描的,也知道哪些Page被访问了,用这个信息来判断该移除哪些Page。
Dirty Page

在Page上有个dirty bit它会告诉我们自从上次它被放入Buffer Pool后,是否有查询对该Page进行了修改,当去判断哪个Page该被移除,并放入新的Page时,最快的方法时找到一个未被标记为dirty的Page,并将它立即移除,将一个新的frame放在Buffer Pool的那个位置上,另一个较慢的方式是,如果Page是dirty的话,我们在移除它之前,必须安全的让其落盘。所以我们要在替换策略上有所取舍,有一些没被标记的Page我们可以即刻将其移除,但是它们可能会在最近被用到,所以如果我不想移除它们,那就只能花费一些时间将Dirty Page落盘,然后再移除Dirty Page
Background Clean

为了避免必须立即让Page落盘的问题,数据库有一个定时任务,它会去Buffer Pool中找到dirty page然后及时把它们落盘,以避免查询线程在执行时因为落盘问题而被阻塞。




