为什么需要Stream
在很多时候我们需要遍历一个集合,根据一些条件从中筛选出我们需要的元素,常规的做法就是用foreach遍历,在foreach块里做判断来筛选。而Stream提供了一种抽象程度更高的选择,使我们在完成计算任务的时候只需要说明需要完成什么任务,而不是说明如何去实现它。
Stream的特点
1、流不存储元素。这些元素可能存储在底层的集合中,或者是按需生成的。
2、流的操作不会修改其数据源。
3、流的操作时尽可能惰性执行的。这意味着知道需要其结果的时候,操作才会执行。
四大函数式接口
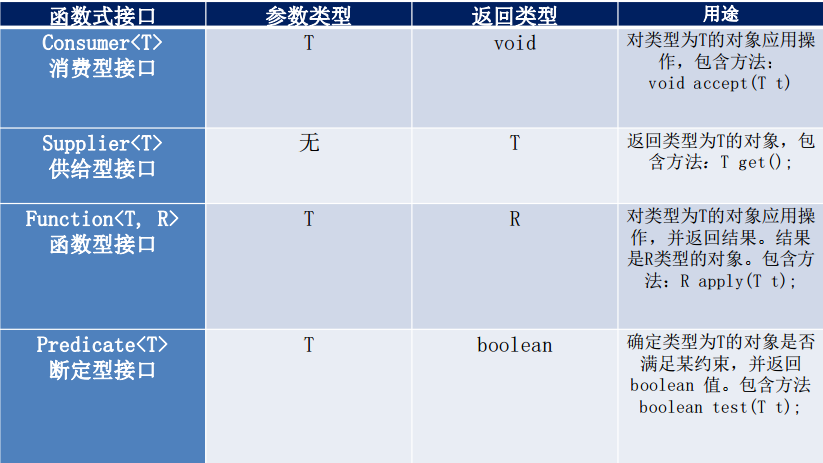
1 | //R apply(T t)函数式接口,一个参数,一个返回值 |
###流的转换方法
流的转换会产生一个新的流,它的元素派生自另一个流中的元素。
1 | Steam<T> filter(Predicate<? super T> predicate) |
fliter方法用于过滤流中的元素,接受的参数是一个判定型接口。
1 | <R> Stream<R> map(Function<? super T,? extends R> mapper) |
map方法用于转换,它将mapper应用于当前流中所有元素所产生的结果。
1 | <R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper) |
flatMap与map基本一致唯一的不同是它返回的是应用mapper后的每一个结果连接起来以后的流。
1 | Stream<T> distinct() |
返回流中所有的不同元素。终结操作
1 | Stream<T> skip(long n) |
返回除了前n个元素的流。终结操作
1 | Stream<T> limit(long maxSize) |
返回前maxSize个元素的流。
1 | Stream<T> sorted() |
无参的sort()返回元素升序排列后的流,有参的需要传一个自定义的比较器。
1 | Optional<T> max(Comparator<? super T> comparator) |
返回这个流的最大最小元素,由传入的比较器决定比较规则。注:这里返回的是Optional对象。终结操作
1 | Optional<T> findAny() |
返回第任意一个元素,返第一个元素。终结操作
1 | boolean allMatch(Predicate<? super T> predicate) |
分别在这个流中所有元素、任意元素和没有任意元素匹配时返回true。终结操作
1 | import lombok.AllArgsConstructor; |
并行流
并行流parallerStream()来自Collection接口所以可以调用parallerStream()来从任何集合中获取并行流
1 | Stream<String> paralleWords = words.parallerStream(); |
也可以将任意顺序流转换为并行流
1 | Stream<String> paralleWords = Stream.of(wordArray).parallel(); |
只要终结方法执行时流处于并行模式,所有的中间流操作就都将被并行化。
当流操作并行运行时,其目标是让其返回结果与顺序执行时返回的结果相同。重要的是这些操作必须是无状态的,并且可以以任意顺序执行。
下面是一个单词计数程序
1 | var shortWords = new int[12]; |
因为多个线程会并发的修改共享的数组,所以这段代码不能计算出正确的结果。这也就引出了一个原则:
- 在做并行计算的时候各个线程之间做的工作应当是不重叠的。
一个正确的处理方式应当是这样
1 | Map<Integer,Long> shortWordCounts = words.parallelStream() |
先按单词长度分组,再统计各个长度的单词的数目,最后合并。
在做并行计算时要注意以下几点:
- 并行化会导致大量的开销,只有面对非常大的数据集才划算。
- 只有在底层的数据源可以被有效的分割成多个部分时,将流并行化才有意义。
- 并行流使用的线程池可能会因诸如文件I/O或者网络访问这样的操作被阻塞而饿死。





