前情回顾
配置是独立于程序的可配变量,同一份程序在不同配置下会有不同的行为。
云原生(Cloud Native)程序的特点
程序的配置,通过设置环境变量传递到容器内部
程序的配置,通过程序启动参数配置生效
程序的配置,通过集中在配置中心进行统一管理(CRUD)
Devops工程师应该做什么?
容器化公司自研的应用程序(通过Docker进行二次封装)
推动容器化应用,转变为云原生应用(一次构建,到处使用)
使用容器编排框架(kubernetes),合理,规范,专业的编排业务容器
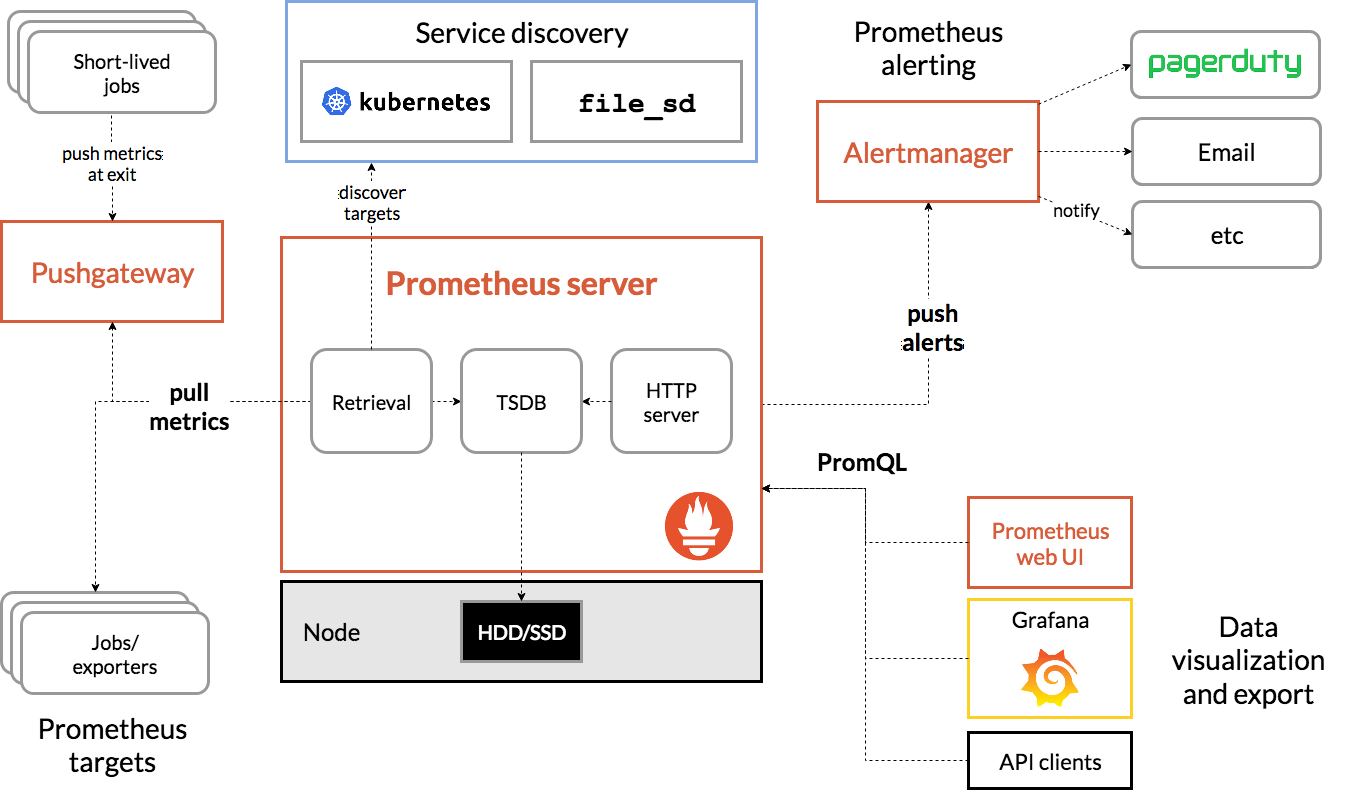
新一代容器云监控Prometheus的概述
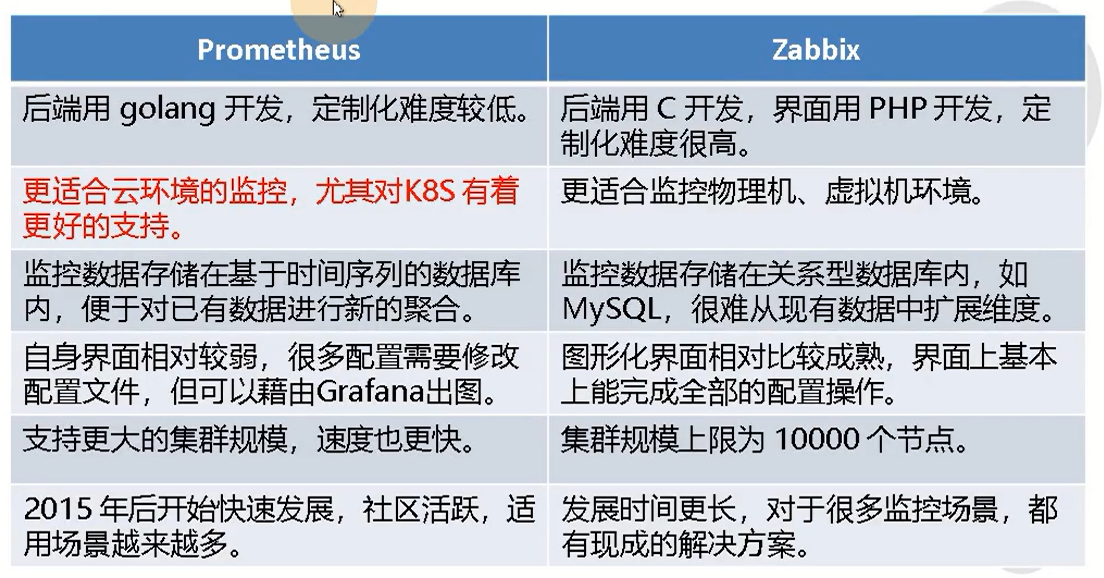
新一代容器云监控系统Prometheus和传统监控Zabbix对比
实战部署容器云监控必备exporter 部署kube-state-metrics 运维主机shkf-245.host.com
准备kube-state-metrics镜像 kube-state-metrics官方quay.io地址
1 2 3 4 5 [root@shkf6-245 ~]# docker pull quay.io/coreos/kube-state-metrics:v1.5.0 [root@shkf6-245 ~]# docker images |grep kube-state-metrics quay.io/coreos/kube-state-metrics v1.5.0 91599517197a 11 months ago 31.8MB [root@shkf6-245 ~]# docker tag 91599517197a harbor.od.com/public/kube-state-metrics:v1.5.0 [root@shkf6-245 ~]# docker push harbor.od.com/public/kube-state-metrics:v1.5.0
准备资源配置清单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 [root@shkf6-245 ~]# mkdir /data/k8s-yaml/kube-state-metrics [root@shkf6-245 ~]# vi /data/k8s-yaml/kube-state-metrics/rbac.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/kube-state-metrics/rbac.yaml apiVersion: v1 kind: ServiceAccount metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: kube-state-metrics namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: kube-state-metrics rules: - apiGroups: - "" resources: - configmaps - secrets - nodes - pods - services - resourcequotas - replicationcontrollers - limitranges - persistentvolumeclaims - persistentvolumes - namespaces - endpoints verbs: - list - watch - apiGroups: - policy resources: - poddisruptionbudgets verbs: - list - watch - apiGroups: - extensions resources: - daemonsets - deployments - replicasets verbs: - list - watch - apiGroups: - apps resources: - statefulsets verbs: - list - watch - apiGroups: - batch resources: - cronjobs - jobs verbs: - list - watch - apiGroups: - autoscaling resources: - horizontalpodautoscalers verbs: - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: kube-state-metrics roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-state-metrics subjects: - kind: ServiceAccount name: kube-state-metrics namespace: kube-system
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 [root@shkf6-245 ~]# vi /data/k8s-yaml/kube-state-metrics/dp.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/kube-state-metrics/dp.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "2" labels: grafanak8sapp: "true" app: kube-state-metrics name: kube-state-metrics namespace: kube-system spec: selector: matchLabels: grafanak8sapp: "true" app: kube-state-metrics strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: labels: grafanak8sapp: "true" app: kube-state-metrics spec: containers: - name: kube-state-metrics image: harbor.od.com/public/kube-state-metrics:v1.5.0 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 name: http-metrics protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /healthz port: 8080 scheme: HTTP initialDelaySeconds: 5 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5 serviceAccountName: kube-state-metrics
应用资源配置清单 1 2 3 4 5 6 [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/kube-state-metrics/rbac.yaml serviceaccount/kube-state-metrics created clusterrole.rbac.authorization.k8s.io/kube-state-metrics created clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/kube-state-metrics/dp.yaml deployment.extensions/kube-state-metrics created
检查启动情况 1 2 3 4 5 [root@shkf6-243 ~]# kubectl get pods -n kube-system|grep kube-state-metrics kube-state-metrics-8669f776c6-n849f 1/1 Running 0 5m13s [root@shkf6-243 ~]# curl 172.6.244.9:8080/healthz ok
部署node-exporter 运维主机shkf6-245.host.com上:
准备node-exporter镜像 node-exporter官方dockerhub地址 node-expoerer官方github地址
1 2 3 4 5 [root@shkf6-245 ~]# docker pull prom/node-exporter:v0.15.0 [root@shkf6-245 ~]# docker images|grep node-exporter prom/node-exporter v0.15.0 12d51ffa2b22 2 years ago 22.8MB [root@shkf6-245 ~]# docker tag 12d51ffa2b22 harbor.od.com/public/node-exporter:v0.15.0 [root@shkf6-245 ~]# docker push harbor.od.com/public/node-exporter:v0.15.0
准备资源配置清单 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 [root@shkf6-245 ~]# mkdir /data/k8s-yaml/node-exporter [root@shkf6-245 ~]# vi /data/k8s-yaml/node-exporter/ds.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/node-exporter/ds.yaml kind: DaemonSet apiVersion: extensions/v1beta1 metadata: name: node-exporter namespace: kube-system labels: daemon: "node-exporter" grafanak8sapp: "true" spec: selector: matchLabels: daemon: "node-exporter" grafanak8sapp: "true" template: metadata: name: node-exporter labels: daemon: "node-exporter" grafanak8sapp: "true" spec: volumes: - name: proc hostPath: path: /proc type: "" - name: sys hostPath: path: /sys type: "" containers: - name: node-exporter image: harbor.od.com/public/node-exporter:v0.15.0 imagePullPolicy: IfNotPresent args: - --path.procfs=/host_proc - --path.sysfs=/host_sys ports: - name: node-exporter hostPort: 9100 containerPort: 9100 protocol: TCP volumeMounts: - name: sys readOnly: true mountPath: /host_sys - name: proc readOnly: true mountPath: /host_proc hostNetwork: true
应用资源配置清单 1 [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/node-exporter/ds.yaml
检查启动情况 1 2 3 4 [root@shkf6-243 ~]# netstat -lntup|grep 9100 tcp6 0 0 :::9100 :::* LISTEN 25846/node_exporter [root@shkf6-243 ~]# curl localhost:9100/metrics
部署cadvisor 运维主机shkf6-245.host.com上:
准备cadvisor镜像 cadvisor官方dockerhub地址 cadvisor官方github地址
1 2 3 4 5 [root@shkf6-245 ~]# docker pull google/cadvisor:v0.28.3 [root@shkf6-245 ~]# docker images |grep cadvisor google/cadvisor v0.28.3 75f88e3ec333 2 years ago 62.2MB [root@shkf6-245 ~]# docker tag 75f88e3ec333 harbor.od.com/public/cadvisor:v0.28.3 [root@shkf6-245 ~]# docker push harbor.od.com/public/cadvisor:v0.28.3
准备资源配置清单 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 [root@shkf6-245 ~]# mkdir /data/k8s-yaml/cadvisor [root@shkf6-245 ~]# vi /data/k8s-yaml/cadvisor/ds.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/cadvisor/ds.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: cadvisor namespace: kube-system labels: app: cadvisor spec: selector: matchLabels: name: cadvisor template: metadata: labels: name: cadvisor spec: hostNetwork: true tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: cadvisor image: harbor.od.com/public/cadvisor:v0.28.3 imagePullPolicy: IfNotPresent volumeMounts: - name: rootfs mountPath: /rootfs readOnly: true - name: var-run mountPath: /var/run - name: sys mountPath: /sys readOnly: true - name: docker mountPath: /var/lib/docker readOnly: true ports: - name: http containerPort: 4194 protocol: TCP readinessProbe: tcpSocket: port: 4194 initialDelaySeconds: 5 periodSeconds: 10 args: - --housekeeping_interval=10s - --port=4194 terminationGracePeriodSeconds: 30 volumes: - name: rootfs hostPath: path: / - name: var-run hostPath: path: /var/run - name: sys hostPath: path: /sys - name: docker hostPath: path: /data/docker
修改运算节点软连接 所有运算节点上:
1 2 ~]# mount -o remount,rw /sys/fs/cgroup/ ~]# ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
应用资源配置清单 任意运算节点上:
1 [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/cadvisor/ds.yaml
检查启动情况 1 2 [root@shkf6-243 ~]# netstat -luntp|grep 4194 tcp6 0 0 :::4194 :::* LISTEN 18027/cadvisor
污点:
1 https://kubernetes.io/zh/docs/concepts/configuration/taint-and-toleration/
部署blackbox-exporter 运维主机shkf6-245.host.com上:
准备blackbox-exporter镜像 blackbox-exporter官方dockerhub地址 blackbox-exporter官方github地址
1 2 3 4 5 [root@shkf6-245 ~]# docker pull prom/blackbox-exporter:v0.15.1 [root@shkf6-245 ~]# docker images|grep blackbox prom/blackbox-exporter v0.15.1 81b70b6158be 3 months ago 19.7MB [root@shkf6-245 ~]# docker tag 81b70b6158be harbor.od.com/public/blackbox-exporter:v0.15.1 [root@shkf6-245 ~]# docker push harbor.od.com/public/blackbox-exporter:v0.15.1
准备资源配置清单
创建目录
1 [root@shkf6-245 ~]# mkdir /data/k8s-yaml/blackbox-exporter
ConfigMap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 [root@shkf6-245 ~]# vi /data/k8s-yaml/blackbox-exporter/cm.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/blackbox-exporter/cm.yaml apiVersion: v1 kind: ConfigMap metadata: labels: app: blackbox-exporter name: blackbox-exporter namespace: kube-system data: blackbox.yml: |- modules: http_2xx: prober: http timeout: 2s http: valid_http_versions: ["HTTP/1.1", "HTTP/2"] valid_status_codes: [200,301,302] method: GET preferred_ip_protocol: "ip4" tcp_connect: prober: tcp timeout: 2s
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 [root@shkf6-245 ~]# vi /data/k8s-yaml/blackbox-exporter/dp.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/blackbox-exporter/dp.yaml kind: Deployment apiVersion: extensions/v1beta1 metadata: name: blackbox-exporter namespace: kube-system labels: app: blackbox-exporter annotations: deployment.kubernetes.io/revision: 1 spec: replicas: 1 selector: matchLabels: app: blackbox-exporter template: metadata: labels: app: blackbox-exporter spec: volumes: - name: config configMap: name: blackbox-exporter defaultMode: 420 containers: - name: blackbox-exporter image: harbor.od.com/public/blackbox-exporter:v0.15.1 imagePullPolicy: IfNotPresent args: - --config.file=/etc/blackbox_exporter/blackbox.yml - --log.level=info - --web.listen-address=:9115 ports: - name: blackbox-port containerPort: 9115 protocol: TCP resources: limits: cpu: 200m memory: 256Mi requests: cpu: 100m memory: 50Mi volumeMounts: - name: config mountPath: /etc/blackbox_exporter readinessProbe: tcpSocket: port: 9115 initialDelaySeconds: 5 timeoutSeconds: 5 periodSeconds: 10 successThreshold: 1 failureThreshold: 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@shkf6-245 ~]# vi /data/k8s-yaml/blackbox-exporter/svc.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/blackbox-exporter/svc.yaml kind: Service apiVersion: v1 metadata: name: blackbox-exporter namespace: kube-system spec: selector: app: blackbox-exporter ports: - name: blackbox-port protocol: TCP port: 9115
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@shkf6-245 ~]# vi /data/k8s-yaml/blackbox-exporter/ingress.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/blackbox-exporter/ingress.yaml apiVersion: extensions/v1beta1 kind: Ingress metadata: name: blackbox-exporter namespace: kube-system spec: rules: - host: blackbox.od.com http: paths: - path: / backend: serviceName: blackbox-exporter servicePort: blackbox-port
应用资源配置清单 1 2 3 4 5 6 7 8 [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/cm.yaml configmap/blackbox-exporter created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/dp.yaml deployment.extensions/blackbox-exporter created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/svc.yaml service/blackbox-exporter created ^[[A[root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/blackbox-exporter/ingress.yaml ingress.extensions/blackbox-exporter created
解析域名 1 2 [root@shkf6-241 ~]# tail -1 /var/named/od.com.zone blackbox A 192.168.6.66
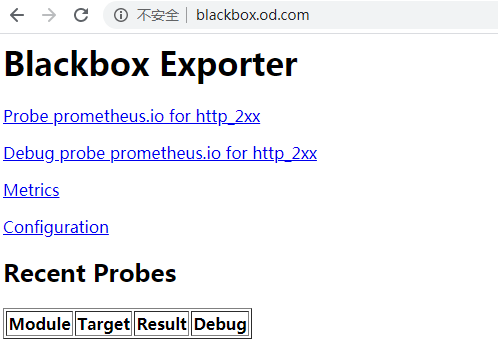
浏览器访问 http://blackbox.od.com/
实战部署Prometheus及其配置详解 部署prometheus 运维主机shkf6-245.host.com上:
准备prometheus镜像 prometheus官方dockerhub地址 prometheus官方github地址
1 2 3 4 5 [root@shkf6-245 ~]# docker pull prom/prometheus:v2.14.0 [root@shkf6-245 ~]# docker images |grep prometheus prom/prometheus v2.14.0 7317640d555e 5 weeks ago 130MB [root@shkf6-245 ~]# docker tag 7317640d555e harbor.od.com/infra/prometheus:v2.12.0 [root@shkf6-245 ~]# docker push harbor.od.com/infra/prometheus:v2.12.0
准备资源配置清单 运维主机shkf6-245.host.com上:
1 [root@shkf6-245 ~]# mkdir /data/k8s-yaml/prometheus
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 [root@shkf6-245 ~]# vi /data/k8s-yaml/prometheus/rbac.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/prometheus/rbac.yaml apiVersion: v1 kind: ServiceAccount metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: prometheus namespace: infra --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: prometheus rules: - apiGroups: - "" resources: - nodes - nodes/metrics - services - endpoints - pods verbs: - get - list - watch - apiGroups: - "" resources: - configmaps verbs: - get - nonResourceURLs: - /metrics verbs: - get --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: infra
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 [root@shkf6-245 ~]# vi /data/k8s-yaml/prometheus/dp.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/prometheus/dp.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "5" labels: name: prometheus name: prometheus namespace: infra spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 7 selector: matchLabels: app: prometheus strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 type: RollingUpdate template: metadata: labels: app: prometheus spec: nodeName: shkf6-243.host.com containers: - name: prometheus image: harbor.od.com/infra/prometheus:v2.12.0 imagePullPolicy: IfNotPresent command: - /bin/prometheus args: - --config.file=/data/etc/prometheus.yml - --storage.tsdb.path=/data/prom-db - --storage.tsdb.min-block-duration=10m - --storage.tsdb.retention=72h ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /data name: data resources: requests: cpu: "1000m" memory: "1.5Gi" limits: cpu: "2000m" memory: "3Gi" imagePullSecrets: - name: harbor securityContext: runAsUser: 0 serviceAccountName: prometheus volumes: - name: data nfs: server: shkf6-245 path: /data/nfs-volume/prometheus
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@shkf6-245 ~]# vi /data/k8s-yaml/prometheus/svc.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/prometheus/svc.yaml apiVersion: v1 kind: Service metadata: name: prometheus namespace: infra spec: ports: - port: 9090 protocol: TCP targetPort: 9090 selector: app: prometheus
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [root@shkf6-245 ~]# vi /data/k8s-yaml/prometheus/ingress.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/prometheus/ingress.yaml apiVersion: extensions/v1beta1 kind: Ingress metadata: annotations: kubernetes.io/ingress.class: traefik name: prometheus namespace: infra spec: rules: - host: prometheus.od.com http: paths: - path: / backend: serviceName: prometheus servicePort: 9090
准备promentheus的配置文件 运维主机shkf6-245.host.com上:
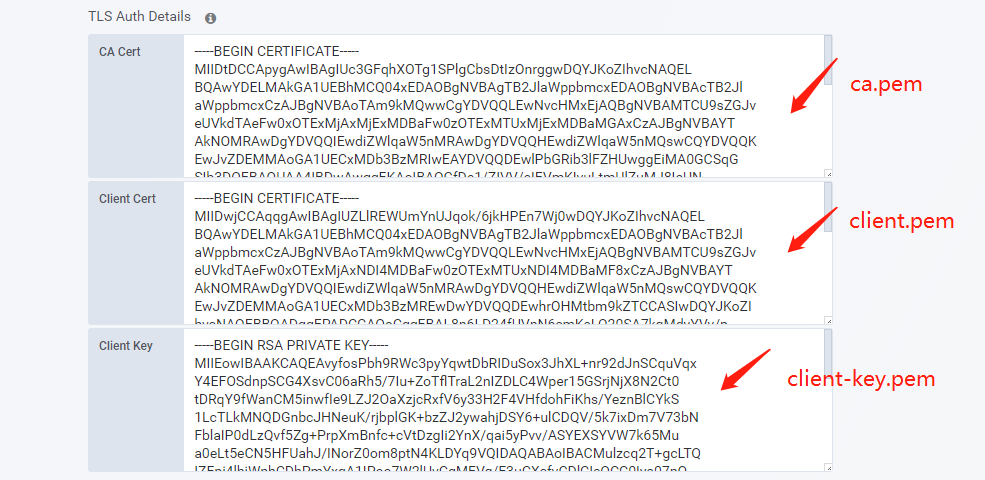
1 2 3 4 5 6 [root@shkf6-245 ~]# mkdir -pv /data/nfs-volume/prometheus/{etc,prom-db} mkdir: created directory ‘/data/nfs-volume/prometheus/etc’ mkdir: created directory ‘/data/nfs-volume/prometheus/prom-db’ [root@shkf6-245 ~]# cp /opt/certs/ca.pem /data/nfs-volume/prometheus/etc/ [root@shkf6-245 ~]# cp /opt/certs/client.pem /data/nfs-volume/prometheus/etc/ [root@shkf6-245 ~]# cp /opt/certs/client-key.pem /data/nfs-volume/prometheus/etc/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 [root@shkf6-245 ~]# vi /data/nfs-volume/prometheus/etc/prometheus.yml [root@shkf6-245 ~]# cat /data/nfs-volume/prometheus/etc/prometheus.yml global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: - job_name: 'etcd' tls_config: ca_file: /data/etc/ca.pem cert_file: /data/etc/client.pem key_file: /data/etc/client-key.pem scheme: https static_configs: - targets: - '192.168.6.242:2379' - '192.168.6.243:2379' - '192.168.6.244:2379' - job_name: 'kubernetes-apiservers' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-pods' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'kubernetes-kubelet' kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __address__ replacement: ${1}:10255 - job_name: 'kubernetes-cadvisor' kubernetes_sd_configs: - role: node relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __address__ replacement: ${1}:4194 - job_name: 'kubernetes-kube-state' kubernetes_sd_configs: - role: pod relabel_configs: - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - source_labels: [__meta_kubernetes_pod_label_grafanak8sapp] regex: .*true.* action: keep - source_labels: ['__meta_kubernetes_pod_label_daemon', '__meta_kubernetes_pod_node_name'] regex: 'node-exporter;(.*)' action: replace target_label: nodename - job_name: 'blackbox_http_pod_probe' metrics_path: /probe kubernetes_sd_configs: - role: pod params: module: [http_2xx] relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme] action: keep regex: http - source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port, __meta_kubernetes_pod_annotation_blackbox_path] action: replace regex: ([^:]+)(?::\d+)?;(\d+);(.+) replacement: $1:$2$3 target_label: __param_target - action: replace target_label: __address__ replacement: blackbox-exporter.kube-system:9115 - source_labels: [__param_target] target_label: instance - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'blackbox_tcp_pod_probe' metrics_path: /probe kubernetes_sd_configs: - role: pod params: module: [tcp_connect] relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_blackbox_scheme] action: keep regex: tcp - source_labels: [__address__, __meta_kubernetes_pod_annotation_blackbox_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __param_target - action: replace target_label: __address__ replacement: blackbox-exporter.kube-system:9115 - source_labels: [__param_target] target_label: instance - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name - job_name: 'traefik' kubernetes_sd_configs: - role: pod relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] action: keep regex: traefik - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name
应用资源配置清单 任意运算节点上:
1 2 3 4 5 6 7 8 9 10 [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/prometheus/rbac.yaml serviceaccount/prometheus created clusterrole.rbac.authorization.k8s.io/prometheus created clusterrolebinding.rbac.authorization.k8s.io/prometheus created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/prometheus/dp.yaml deployment.extensions/prometheus created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/prometheus/svc.yaml service/prometheus created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/prometheus/ingress.yaml ingress.extensions/prometheus created
解析域名 在shkf6-241.host.com上:
1 2 [root@shkf6-241 ~]# tail -1 /var/named/od.com.zone prometheus A 192.168.6.66
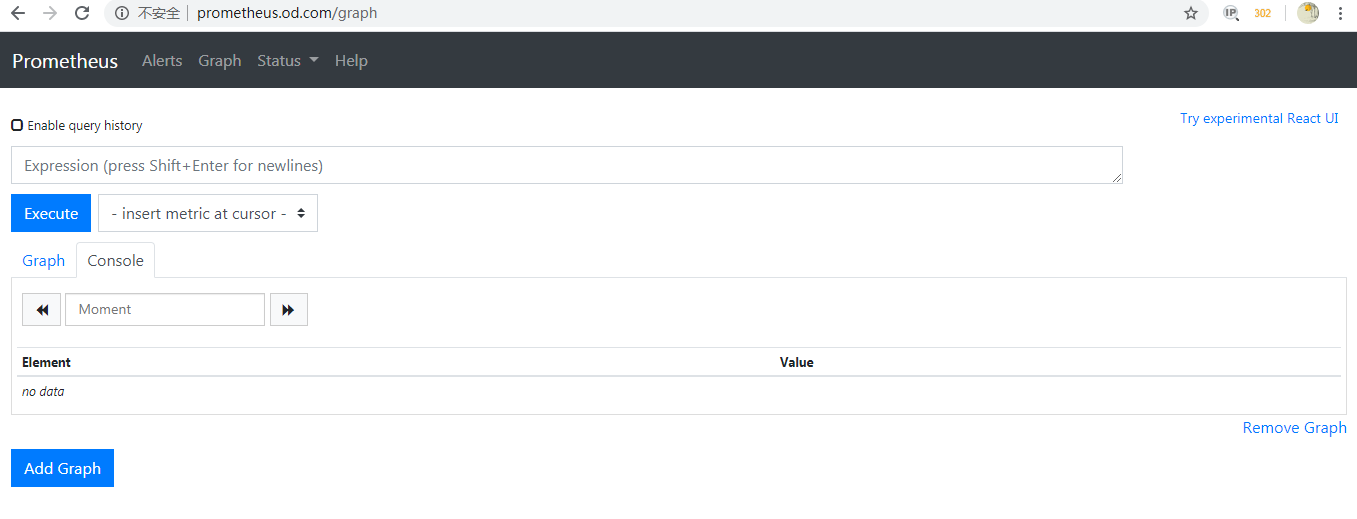
浏览器访问 http://prometheus.od.com
Prometheus监控内容 Targets(jobs)
etcd
监控etcd服务
key
value
etcd_server_has_leader
1
etcd_http_failed_total
1
…
….
kubernetes-apiserver
监控apiserver服务
kubernetes-kubelet
监控kubelet服务
kubernetes-kube-state 监控基本信息
监控Node节点信息
监控pod信息
traefik
监控traefik-ingress-controller
key
value
traefik_entrypoint_requests_total{code=”200”,entrypoint=”http”,method=”PUT”,protocol=”http”}
138
traefik_entrypoint_requests_total{code=”200”,entrypoint=”http”,method=”GET”,protocol=”http”}
285
traefik_entrypoint_open_connections{entrypoint=”http”,method=”PUT”,protocol=”http”}
1
…
…
注意:在traefik的pod控制器上加annotations,并重启pod,监控生效
配置范例:
1 2 3 4 5 "annotations": { "prometheus_io_scheme": "traefik", "prometheus_io_path": "/metrics", "prometheus_io_port": "8080" }
blackbox* 监控服务是否存活
监控tcp协议服务是否存活
key
value
probe_success
1
probe_ip_protocol
4
probe_failed_due_to_regex
0
probe_duration_seconds
0.000597546
probe_dns_lookup_time_seconds
0.00010898
注意:在pod控制器上加annotations,并重启pod,监控生效
配置范例:
1 2 3 4 "annotations": { "blackbox_port": "20880", "blackbox_scheme": "tcp" }
监控http协议服务是否存活
key
value
probe_success
1
probe_ip_protocol
4
probe_http_version
1.1
probe_http_status_code
200
probe_http_ssl
0
probe_http_redirects
1
probe_http_last_modified_timestamp_seconds
1.553861888e+09
probe_http_duration_seconds{phase=”transfer”}
0.000238343
probe_http_duration_seconds{phase=”tls”}
0
probe_http_duration_seconds{phase=”resolve”}
5.4095e-05
probe_http_duration_seconds{phase=”processing”}
0.000966104
probe_http_duration_seconds{phase=”connect”}
0.000520821
probe_http_content_length
716
probe_failed_due_to_regex
0
probe_duration_seconds
0.00272609
probe_dns_lookup_time_seconds
5.4095e-05
注意:在pod控制器上加annotations,并重启pod,监控生效
配置范例:
1 2 3 4 5 "annotations": { "blackbox_path": "/", "blackbox_port": "8080", "blackbox_scheme": "http" }
kubernetes-pods*
监控JVM信息
key
value
jvm_info{version=”1.7.0_80-b15”,vendor=”Oracle Corporation”,runtime=”Java(TM) SE Runtime Environment”,}
1.0
jmx_config_reload_success_total
0.0
process_resident_memory_bytes
4.693897216E9
process_virtual_memory_bytes
1.2138840064E10
process_max_fds
65536.0
process_open_fds
123.0
process_start_time_seconds
1.54331073249E9
process_cpu_seconds_total
196465.74
jvm_buffer_pool_used_buffers{pool=”mapped”,}
0.0
jvm_buffer_pool_used_buffers{pool=”direct”,}
150.0
jvm_buffer_pool_capacity_bytes{pool=”mapped”,}
0.0
jvm_buffer_pool_capacity_bytes{pool=”direct”,}
6216688.0
jvm_buffer_pool_used_bytes{pool=”mapped”,}
0.0
jvm_buffer_pool_used_bytes{pool=”direct”,}
6216688.0
jvm_gc_collection_seconds_sum{gc=”PS MarkSweep”,}
1.867
…
…
注意:在pod控制器上加annotations,并重启pod,监控生效
配置范例:
1 2 3 4 5 "annotations": { "prometheus_io_scrape": "true", "prometheus_io_port": "12346", "prometheus_io_path": "/" }
修改traefik服务接入prometheus监控 dashboard上:
1 2 3 4 5 "annotations": { "prometheus_io_scheme": "traefik", "prometheus_io_path": "/metrics", "prometheus_io_port": "8080" }
删除pod,重启traefik,观察监控
继续添加blackbox监控配置项
1 2 3 4 5 6 7 8 "annotations": { "prometheus_io_scheme": "traefik", "prometheus_io_path": "/metrics", "prometheus_io_port": "8080", "blackbox_path": "/", "blackbox_port": "8080", "blackbox_scheme": "http" }
修改dubbo-service服务接入prometheus监控 dashboard上:
1 2 3 4 5 6 7 "annotations": { "prometheus_io_scrape": "true", "prometheus_io_path": "/", "prometheus_io_port": "12346", "blackbox_port": "20880", "blackbox_scheme": "tcp" }
删除pod,重启traefik,观察监控
修改dubbo-consumer服务接入prometheus监控 app名称空间->deployment->dubbo-demo-consumer->spec->template->metadata下,添加
1 2 3 4 5 6 7 8 "annotations": { "prometheus_io_scrape": "true", "prometheus_io_path": "/", "prometheus_io_port": "12346", "blackbox_path": "/hello", "blackbox_port": "8080", "blackbox_scheme": "http" }
删除pod,重启traefik,观察监控
实战部署容器云监控展示平台Grafana 运维主机shkf6-245.host.com上:
准备grafana镜像 grafana官方dockerhub地址 grafana官方github地址 grafana官网
1 2 3 4 5 [root@shkf6-245 ~]# docker pull grafana/grafana:5.4.2 [root@shkf6-245 ~]# docker images |grep grafana grafana/grafana 5.4.2 6f18ddf9e552 12 months ago 243MB [root@shkf6-245 ~]# docker tag 6f18ddf9e552 harbor.od.com/infra/grafana:v5.4.2 [root@shkf6-245 ~]# docker push harbor.od.com/infra/grafana:v5.4.2
准备资源配置清单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [root@shkf6-245 ~]# vi /data/k8s-yaml/grafana/rbac.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/grafana/rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: grafana rules: - apiGroups: - "*" resources: - namespaces - deployments - pods verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/cluster-service: "true" name: grafana roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: grafana subjects: - kind: User name: k8s-node
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 [root@shkf6-245 ~]# mkdir /data/nfs-volume/grafana [root@shkf6-245 ~]# vi /data/k8s-yaml/grafana/dp.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/grafana/dp.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: grafana name: grafana name: grafana namespace: infra spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 7 selector: matchLabels: name: grafana strategy: rollingUpdate: maxSurge: 1 maxUnavailable: 1 type: RollingUpdate template: metadata: labels: app: grafana name: grafana spec: containers: - name: grafana image: harbor.od.com/infra/grafana:v5.4.2 imagePullPolicy: IfNotPresent ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /var/lib/grafana name: data imagePullSecrets: - name: harbor securityContext: runAsUser: 0 volumes: - nfs: server: shkf6-245 path: /data/nfs-volume/grafana name: data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [root@shkf6-245 ~]# vi /data/k8s-yaml/grafana/svc.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/grafana/svc.yaml apiVersion: v1 kind: Service metadata: name: grafana namespace: infra spec: ports: - port: 3000 protocol: TCP targetPort: 3000 selector: app: grafana
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@shkf6-245 ~]# vi /data/k8s-yaml/grafana/ingress.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/grafana/ingress.yaml apiVersion: extensions/v1beta1 kind: Ingress metadata: name: grafana namespace: infra spec: rules: - host: grafana.od.com http: paths: - path: / backend: serviceName: grafana servicePort: 3000
应用资源配置清单 任意运算节点上:
1 2 3 4 5 6 7 8 9 [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/grafana/rbac.yaml clusterrole.rbac.authorization.k8s.io/grafana created clusterrolebinding.rbac.authorization.k8s.io/grafana created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/grafana/dp.yaml deployment.extensions/grafana created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/grafana/svc.yaml service/grafana created [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/grafana/ingress.yaml ingress.extensions/grafana created
解析域名 1 2 [root@shkf6-241 ~]# tail -1 /var/named/od.com.zone grafana A 192.168.6.66
浏览器访问 http://grafana.od.com
登录后需要修改管理员密码
配置grafana页面 外观 Configuration -> Preferences
Light
Default
Local browser time
save
插件 Configuration -> Plugins
安装方法一:
1 grafana-cli plugins install grafana-kubernetes-app
安装方法二:
下载地址
1 2 3 [root@shkf6-245 ~]# cd /data/nfs-volume/grafana/plugins [root@shkf6-245 plugins]# wget https://grafana.com/api/plugins/grafana-kubernetes-app/versions/1.0.1/download -O grafana-kubernetes-app.zip [root@shkf6-245 plugins]# unzip grafana-kubernetes-app.zip
安装方法一:
1 grafana-cli plugins install grafana-clock-panel
安装方法二:
下载地址
安装方法一:
1 grafana-cli plugins install grafana-piechart-panel
安装方法二:
下载地址
1 grafana-cli plugins install briangann-gauge-panel
安装方法二:
下载地址
安装方法一:
1 grafana-cli plugins install natel-discrete-panel
安装方法二:
下载地址
配置grafana数据源 Configuration -> Data Sources
配置Kubernetes集群Dashboard
kubernetes -> +New Cluster
key
value
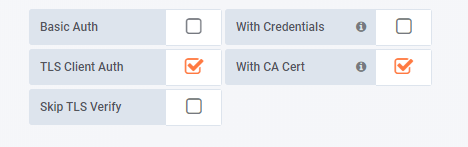
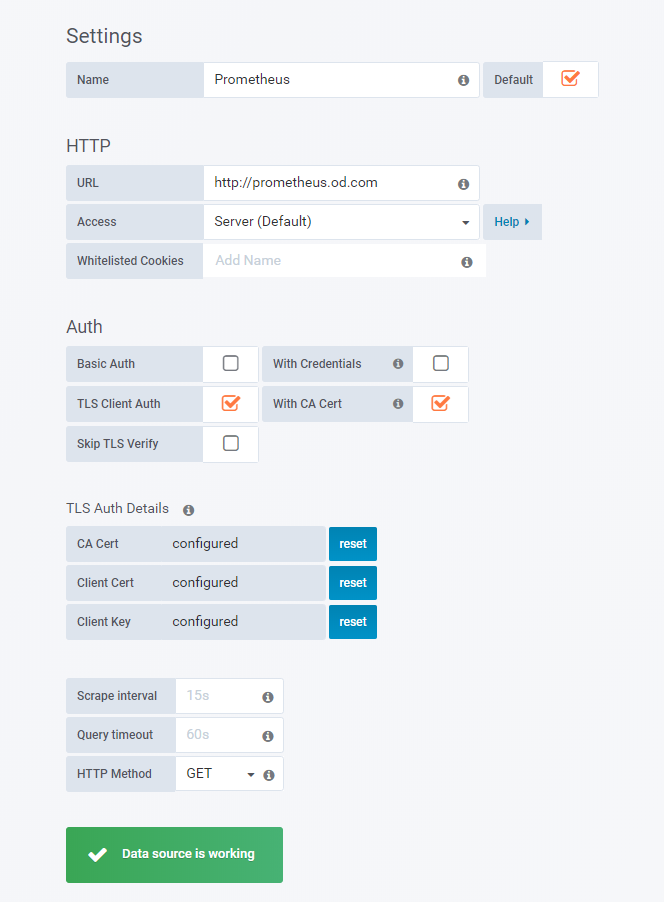
TLS Client Auth
勾选
With Ca Cert
勾选
将ca.pem、client.pem和client-key.pem粘贴至文本框内
key
value
Datasource
Prometheus
注意:
K8S Container中,所有Pannel的
实战通过Alertmanager组件进行监控告警 准备Alertmanager镜像 在运维主机上:
1 2 3 4 5 [root@shkf6-245 ~]# docker pull docker.io/prom/alertmanager:v0.14.0 [root@shkf6-245 ~]# docker images |grep alertmanager prom/alertmanager v0.14.0 23744b2d645c 22 months ago 31.9MB [root@shkf6-245 ~]# docker tag 23744b2d645c harbor.od.com/infra/alertmanager:v0.14.0 [root@shkf6-245 ~]# docker push harbor.od.com/infra/alertmanager:v0.14.0
准备资源配置清单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@shkf6-245 ~]# vi /data/k8s-yaml/alertmanager/cm.yaml [root@shkf6-245 ~]# cat /data/k8s-yaml/alertmanager/cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: alertmanager-config namespace: infra data: config.yml: |- global: resolve_timeout: 5m smtp_smarthost: 'smtp.qq.com:465' smtp_from: '[email protected] ' smtp_auth_username: '[email protected] ' smtp_auth_password: 'pzrjjrntflqeigae' smtp_require_tls: false route: group_by: ['alertname', 'cluster'] group_wait: 30s group_interval: 5m repeat_interval: 5m receiver: default receivers: - name: 'default' email_configs: - to: '[email protected] ' send_resolved: true
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 [root@shkf6-245 ~]# cat /data/k8s-yaml/alertmanager/dp.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: alertmanager namespace: infra spec: replicas: 1 selector: matchLabels: app: alertmanager template: metadata: labels: app: alertmanager spec: containers: - name: alertmanager image: harbor.od.com/infra/alertmanager:v0.14.0 args: - "--config.file=/etc/alertmanager/config.yml" - "--storage.path=/alertmanager" ports: - name: alertmanager containerPort: 9093 volumeMounts: - name: alertmanager-cm mountPath: /etc/alertmanager volumes: - name: alertmanager-cm configMap: name: alertmanager-config imagePullSecrets: - name: harbor
1 2 3 4 5 6 7 8 9 10 11 12 [root@shkf6-245 ~]# cat /data/k8s-yaml/alertmanager/svc.yaml apiVersion: v1 kind: Service metadata: name: alertmanager namespace: infra spec: selector: app: alertmanager ports: - port: 80 targetPort: 9093
应用资源配置清单 1 2 3 [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/cm.yaml [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/dp.yaml [root@shkf6-243 ~]# kubectl apply -f http://k8s-yaml.od.com/alertmanager/svc.yaml
报警规则 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 [root@shkf6-245 ~]# vi /data/nfs-volume/prometheus/etc/rules.yml groups: - name: hostStatsAlert rules: - alert: hostCpuUsageAlert expr: sum(avg without (cpu)(irate(node_cpu{mode!='idle'}[5m]))) by (instance) > 0.85 for: 5m labels: severity: warning annotations: summary: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }}%)" - alert: hostMemUsageAlert expr: (node_memory_MemTotal - node_memory_MemAvailable)/node_memory_MemTotal > 0.85 for: 5m labels: severity: warning annotations: summary: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }}%)" - alert: OutOfInodes expr: node_filesystem_free{fstype="overlay",mountpoint ="/"} / node_filesystem_size{fstype="overlay",mountpoint ="/"} * 100 < 10 for: 5m labels: severity: warning annotations: summary: "Out of inodes (instance {{ $labels.instance }})" description: "Disk is almost running out of available inodes (< 10% left) (current value: {{ $value }})" - alert: OutOfDiskSpace expr: node_filesystem_free{fstype="overlay",mountpoint ="/rootfs"} / node_filesystem_size{fstype="overlay",mountpoint ="/rootfs"} * 100 < 10 for: 5m labels: severity: warning annotations: summary: "Out of disk space (instance {{ $labels.instance }})" description: "Disk is almost full (< 10% left) (current value: {{ $value }})" - alert: UnusualNetworkThroughputIn expr: sum by (instance) (irate(node_network_receive_bytes[2m])) / 1024 / 1024 > 100 for: 5m labels: severity: warning annotations: summary: "Unusual network throughput in (instance {{ $labels.instance }})" description: "Host network interfaces are probably receiving too much data (> 100 MB/s) (current value: {{ $value }})" - alert: UnusualNetworkThroughputOut expr: sum by (instance) (irate(node_network_transmit_bytes[2m])) / 1024 / 1024 > 100 for: 5m labels: severity: warning annotations: summary: "Unusual network throughput out (instance {{ $labels.instance }})" description: "Host network interfaces are probably sending too much data (> 100 MB/s) (current value: {{ $value }})" - alert: UnusualDiskReadRate expr: sum by (instance) (irate(node_disk_bytes_read[2m])) / 1024 / 1024 > 50 for: 5m labels: severity: warning annotations: summary: "Unusual disk read rate (instance {{ $labels.instance }})" description: "Disk is probably reading too much data (> 50 MB/s) (current value: {{ $value }})" - alert: UnusualDiskWriteRate expr: sum by (instance) (irate(node_disk_bytes_written[2m])) / 1024 / 1024 > 50 for: 5m labels: severity: warning annotations: summary: "Unusual disk write rate (instance {{ $labels.instance }})" description: "Disk is probably writing too much data (> 50 MB/s) (current value: {{ $value }})" - alert: UnusualDiskReadLatency expr: rate(node_disk_read_time_ms[1m]) / rate(node_disk_reads_completed[1m]) > 100 for: 5m labels: severity: warning annotations: summary: "Unusual disk read latency (instance {{ $labels.instance }})" description: "Disk latency is growing (read operations > 100ms) (current value: {{ $value }})" - alert: UnusualDiskWriteLatency expr: rate(node_disk_write_time_ms[1m]) / rate(node_disk_writes_completedl[1m]) > 100 for: 5m labels: severity: warning annotations: summary: "Unusual disk write latency (instance {{ $labels.instance }})" description: "Disk latency is growing (write operations > 100ms) (current value: {{ $value }})" - name: http_status rules: - alert: ProbeFailed expr: probe_success == 0 for: 1m labels: severity: error annotations: summary: "Probe failed (instance {{ $labels.instance }})" description: "Probe failed (current value: {{ $value }})" - alert: StatusCode expr: probe_http_status_code <= 199 OR probe_http_status_code >= 400 for: 1m labels: severity: error annotations: summary: "Status Code (instance {{ $labels.instance }})" description: "HTTP status code is not 200-399 (current value: {{ $value }})" - alert: SslCertificateWillExpireSoon expr: probe_ssl_earliest_cert_expiry - time() < 86400 * 30 for: 5m labels: severity: warning annotations: summary: "SSL certificate will expire soon (instance {{ $labels.instance }})" description: "SSL certificate expires in 30 days (current value: {{ $value }})" - alert: SslCertificateHasExpired expr: probe_ssl_earliest_cert_expiry - time() <= 0 for: 5m labels: severity: error annotations: summary: "SSL certificate has expired (instance {{ $labels.instance }})" description: "SSL certificate has expired already (current value: {{ $value }})" - alert: BlackboxSlowPing expr: probe_icmp_duration_seconds > 2 for: 5m labels: severity: warning annotations: summary: "Blackbox slow ping (instance {{ $labels.instance }})" description: "Blackbox ping took more than 2s (current value: {{ $value }})" - alert: BlackboxSlowRequests expr: probe_http_duration_seconds > 2 for: 5m labels: severity: warning annotations: summary: "Blackbox slow requests (instance {{ $labels.instance }})" description: "Blackbox request took more than 2s (current value: {{ $value }})" - alert: PodCpuUsagePercent expr: sum(sum(label_replace(irate(container_cpu_usage_seconds_total[1m]),"pod","$1","container_label_io_kubernetes_pod_name", "(.*)"))by(pod) / on(pod) group_right kube_pod_container_resource_limits_cpu_cores *100 )by(container,namespace,node,pod,severity) > 80 for: 5m labels: severity: warning annotations: summary: "Pod cpu usage percent has exceeded 80% (current value: {{ $value }}%)"
prometheus加载报警规则
1 2 3 4 5 6 7 8 [root@shkf6-245 ~]# vim /data/nfs-volume/prometheus/etc/prometheus.yml alerting: alertmanagers: - static_configs: - targets: ["alertmanager"] rule_files: - "/data/etc/rules.yml"
1 2 3 4 5 [root@shkf6-243 ~]# ps -ef|grep prometheus root 14240 14221 1 Dec24 ? 00:15:22 traefik traefik --api --kubernetes --logLevel=INFO --insecureskipverify=true --kubernetes.endpoint=https://192.168.6.66:7443 --accesslog --accesslog.filepath=/var/log/traefik_access.log --traefiklog --traefiklog.filepath=/var/log/traefik.log --metrics.prometheus root 23839 23821 11 Dec24 ? 02:57:21 /bin/prometheus --config.file=/data/etc/prometheus.yml --storage.tsdb.path=/data/prom-db --storage.tsdb.min-block-duration=10m --storage.tsdb.retention=72h root 25825 23546 0 10:28 pts/1 00:00:00 grep --color=auto prometheus [root@shkf6-243 ~]# kill -SIGHUP 23839
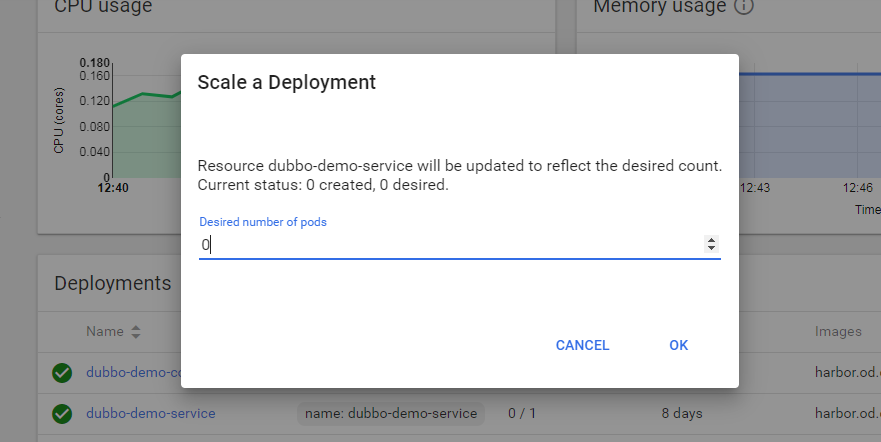
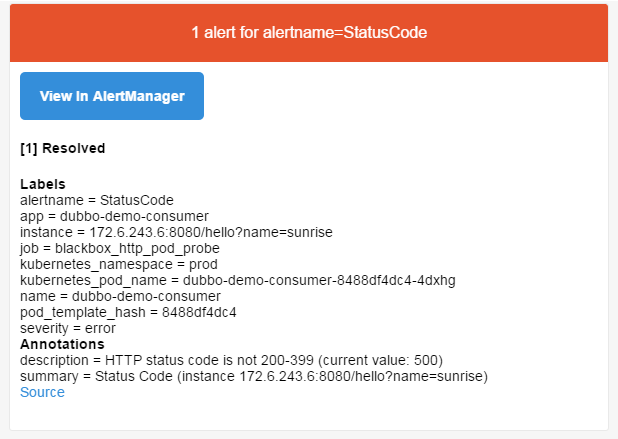
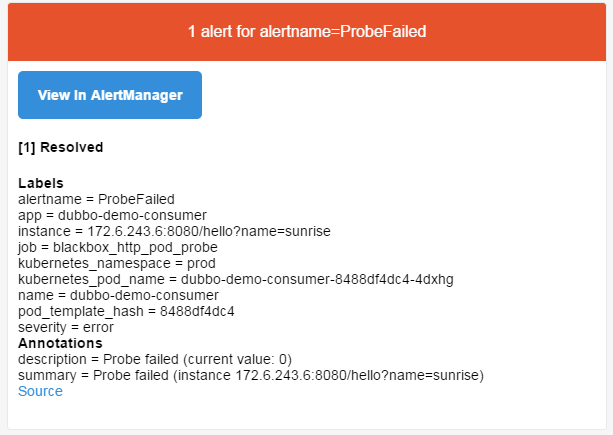
验证报警 a.副本数缩为0
b.等待1分钟,查看邮件
钉钉报警 https://github.com/cnych/alertmanager-dingtalk-hook
https://www.cnblogs.com/wangxu01/articles/11654836.html